Laurel or Yanny?
Same audio, different perception
In May 2018, social media exploded after the surfacing of an audio clip that some perceived as Laurel, but others as Yanny. Listen and decide for yourself:
Laurel/Yanny – [original]
#Laurelgate was quickly seen as the auditory version of #TheDress, a photo going viral in 2015 of a white and gold dress, or was it black and blue? But how fixed is this divide between individuals? Can we turn #Yannists into #Laurelites, and vice versa?
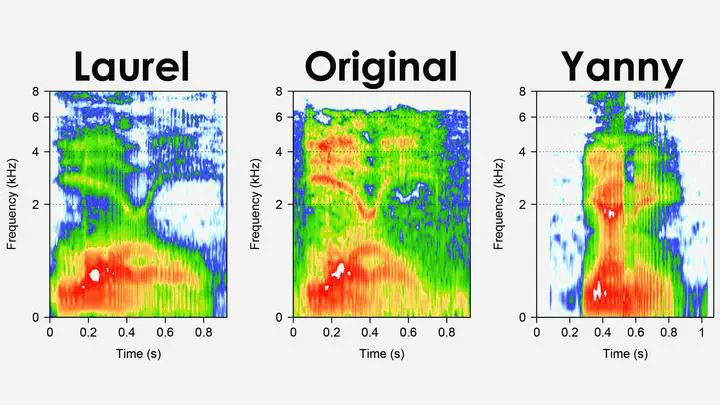
Higher vs. lower frequencies
Acoustic analysis of the original clip suggests that the higher frequencies (>1000 Hz) resembled the word Yanny, but the lower frequencies (<1000 Hz) are more like Laurel. This can be seen in the figure at the top of this page, where the upper part of the middle panel (Original) is more like the right panel (Yanny), but the lower part is more like the left panel (Laurel). This is best demonstrated by artificially emphasizing/attenuating the higher vs. lower frequencies in the audio clip.
In these sounds below, we gradually attenuate (~turn down) the higher frequencies while we simultaneously emphasize (~turn up) the lower frequencies. Play the sounds below, can you hear Laurel turning into Yanny?
Click here for audio specs
- Middle clip: original Laurel/Yanny clip
- Manipulation: filtered by 10 bandpass filters (with center frequencies: 31.5, 63, 125, 250, 500, 1000, 2000, 4000, 8000, 16000 Hz; using a Hann window with a roll-off width of 20, 20, 40, 80, 100, 100, 100, 100, 100, 100 Hz, respectively). Inverse intensity manipulation for high (>1000 Hz) vs. low (<1000 Hz) frequency bands in steps of 6 dB.
- Top clip: -18 dB attenuation for higher frequency bands, +18 dB emphasis for lower frequency bands.
- Bottom clip: +18 dB emphasis for higher frequency bands, -18 dB attenuation for lower frequency bands.
OK, so we can guide what people hear by artificially editing the higher vs. lower frequencies in the clip. But can we also make someone hear one and the same clip differently?
Let’s add Laurel’s telephone number
The perception of speech sounds is influenced by the surrounding acoustic context. The same sound can be perceived differently when, for instance, the acoustics of a preceding sentence are changed. Below, you will hear the original Laurel/Yanny clip, but this time preceded by a telephone number: 496-0356. In the first clip, we filtered out (~removed) the lower frequencies in the telephone number leaving only the high frequency content. In the second clip, we filtered out the higher frequencies leaving only the low frequency content. Note: the Laurel/Yanny clip itself is identical in the two audios. Do you hear a different name after each telephone number?
High-pass filtered telephone number + Laurel/Yanny
Low-pass filtered telephone number + Laurel/Yanny
Numbing your ears
In a crowd-sourced experiment with >500 online participants, we found that the same people were more likely to report hearing Laurel for the first clip, but Yanny for the second clip. This is because the high-frequency content in the telephone number in the first clip ’numbs your ears’ for any following high-frequency content, thus making the lower frequencies stand out more, biasing perception towards Laurel. And vice versa, the low-frequency content in the telephone number in the second clip ’numbs your ears’ for any following low-frequency content, thus making the higher frequencies stand out more, biasing perception towards Yanny.
Really? Convince me…
This is Figure 1 from Bosker (2018, JASA) showing people’s responses in panel C. The blue line shows the proportion of Yanny responses after a high-pass filtered telephone number (~first clip above), which is higher than the red line illustrating people’s responses for the same Laurel/Yanny clips after a low-pass filtered telephone number (~second clip above).

Why is this important?
These social media phenomena are great examples of how our perception of the world is strongly context-dependent. What we perceive is not wholly determined by the input signal alone, but also by the context in which the signal is perceived, including the sounds heard previously, our prior expectations, who is talking, etc. etc. As such, they highlight the subtle intricacies of human perception.
Relevant papers
(2018). Putting Laurel and Yanny in context. The Journal of the Acoustic Society of America, 144(6), EL503-EL508, doi:10.1121/1.5070144.