Paper accepted in Journal of Phonetics!
How do speakers of Dutch produce lexical stress? Read it in: “Your “VOORnaam” is not my “VOORnaam”: An acoustic analysis of individual talker differences in word stress in Dutch.”
Published!
Our paper “Your “VOORnaam” is not my “VOORnaam”: An acoustic analysis of individual talker differences in word stress in Dutch” has recently been published in Journal of Phonetics, authored by Giulio Severijnen, Hans Rutger Bosker, and James McQueen. The fulltext and all data are publicly available at the links provided at the bottom of this post.
What’s it about?
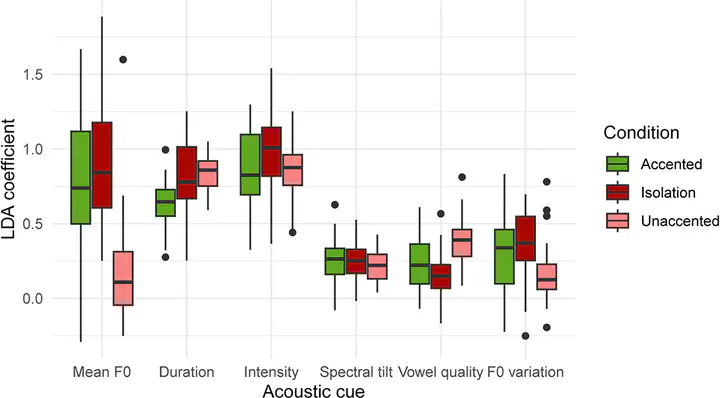
As part of his PhD, Giulio recorded 40 speakers of Dutch producing word pairs that critically differed in stress position, like “VOORnaam” (first name) - “voorNAAM” (respectable). He then measured how a syllable with stress (“VOOR-”) differs acoustically from the same syllable without stress (“voor-”). The figure above (reproducing Figure 3 from the original paper) shows that people generally tend to use pitch, intensity, and duration as primary cues to stress, but this depends in part on the context in which the word is spoken.
More importantly, Giulio saw that each speaker had their own pronunciation preferences. That is, each employed a unique combination of acoustic cues to stress, illustrating large prosodic variability between talkers. In fact, classes of cue-weighting tendencies emerged, differing in which cue was used as the main cue (e.g., ‘pitch-speakers’ vs. ‘intensity-speakers’). This suggests that, while there is a large amount of variability between different speakers (i.e., each talker had a unique set of cue weights), talkers do seem to cluster together regarding which cue is their main cue.
Why is this important?
This study is the most comprehensive acoustic description, to date, of word stress in Dutch. This is valuable information for speech scientists but also informative for speech synthesizers and automatic speech recognition (ASR) systems. Moreover, we describe large prosodic variability between individual talkers, but at the same time this variability isn’t boundless. Listeners, as well as ASR systems, may use this talker-specific information (e.g., “Johnny is a pitch-speaker”) when trying to comprehend new speech from the same talker, especially in challenging listening conditions such as in noise.
Full reference
(2024). Your “VOORnaam” is not my “VOORnaam”: An acoustic analysis of individual talker differences in word stress in Dutch. Journal of Phonetics, 103, 101296, doi:10.1016/j.wocn.2024.101296.